Turning Archaeological Documents into Searchable Knowledge with Cosmos DB Vector Search

📖 The Problem: Field Reports Are Not Agent-Friendly
Archaeological field reports, historical journals, and excavation notes are invaluable—but they’re locked in PDFs and text documents. When our multi-agent AI team (from Blog 4) analyzes satellite imagery or LiDAR data, they need historical context:
- “Has this site been previously surveyed?”
- “What artifacts were found in similar geological formations?”
- “What do historical texts say about settlements in this region?”
Traditional keyword search fails here. An agent searching for “Bronze Age burial mounds” might miss a document that says “Early metallurgical period funerary structures.” We need semantic search—understanding meaning, not just matching words.
This is where Cosmos DB Vector Search transforms unstructured documents into queryable archaeological knowledge.
🏗️ The Architecture: From Documents to Discovery
Inspired by Microsoft’s Logic Apps document indexing pattern, I extended the design for archaeological research:
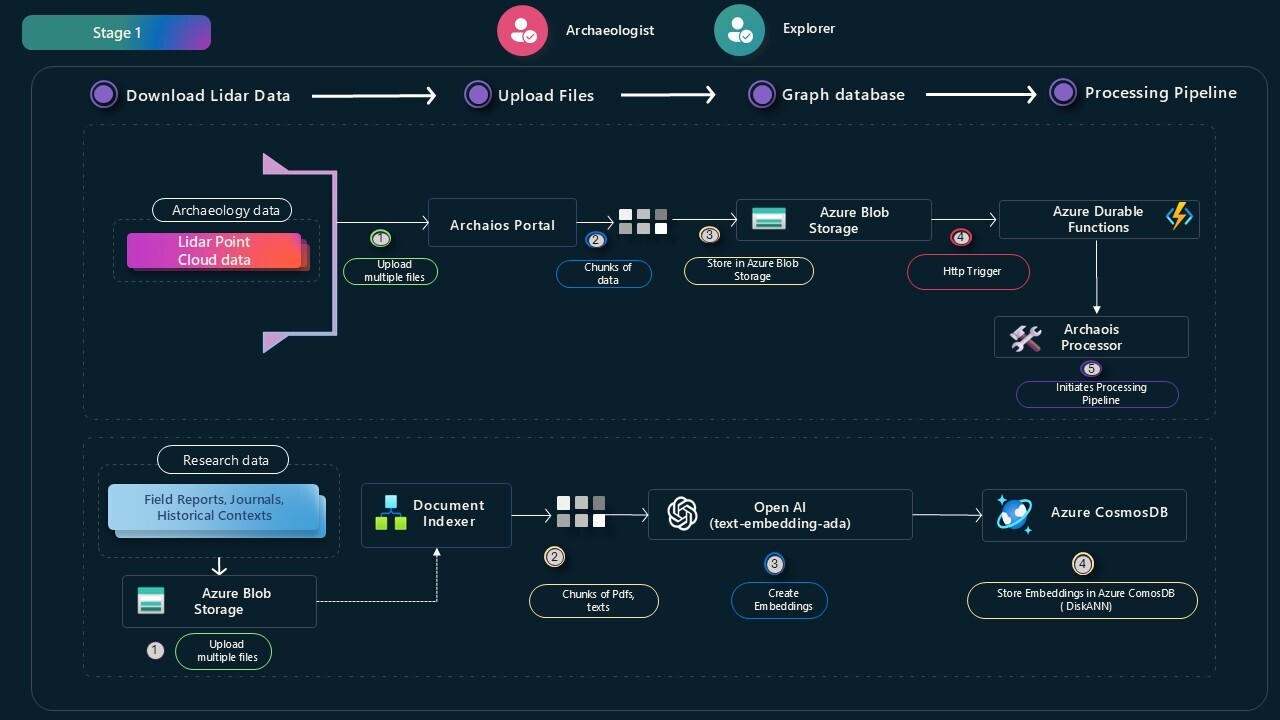
|
|
The key insight: documents become coordinates in semantic space. Similar concepts cluster together, regardless of exact wording.
🔢 Step 1: Vectorizing Historical Knowledge
⚙️ The Embedding Service
At the core, we use Azure OpenAI’s text-embedding-ada-002 model to convert text into 1536-dimensional vectors (think of them as coordinates in “meaning space”):
|
|
Why text-embedding-ada-002?
- High semantic fidelity: Captures nuanced meanings in archaeological terminology
- Cost-effective: Compared to larger embedding models
- Proven at scale: Powers semantic search in production RAG systems
💾 Step 2: Storing Vectors in Cosmos DB
📦 Container Design: archaeologyCorpus
The Cosmos DB container stores document chunks with their vector embeddings:
|
|
Key design decisions:
-
Chunks, not full documents: Large documents (200+ pages) are split into semantically coherent segments. This ensures:
- Precise retrieval (get the exact paragraph, not entire PDF)
- Better context for AI agents (focused information)
-
DiskANN vector index: Cosmos DB’s high-performance approximate nearest neighbor (ANN) algorithm
- Sub-millisecond query latency at scale
- Handles millions of vectors efficiently
- No separate vector database needed
🔍 Step 3: Vector Search Repository
The CosmosDbVectorRepository encapsulates semantic search:
|
|
What’s happening:
VectorDistance(c.vector, @embedding): Cosmos DB’s native vector similarity function- Top N retrieval: Get the 3 most semantically similar document chunks
- Similarity score: Lower scores = higher similarity (cosine distance)
- Dynamic results: Flexible schema for different document types
🤖 Step 4: AI Agent Integration - The Knowledge Plugin
AI agents query historical knowledge through a Semantic Kernel plugin:
|
|
The RAG Pattern in Action:
- User query: “What artifacts were found near water sources in Jordan?”
- Embedding generation: Query → 1536-dimensional vector
- Vector search: Find top 3 similar document chunks in
archaeologyCorpus - Context retrieval: Return relevant field report excerpts
- Agent reasoning: AI agent combines retrieved knowledge with satellite/LiDAR analysis
💡 Why This Matters: Knowledge Multiplies Agent Intelligence

❌ Before Vector Search (Blind Analysis):
|
|
✅ After Vector Search (Context-Aware Analysis):
|
|
The difference: Vector search transformed speculation into evidence-based analysis.
⚙️ Configuration & Deployment
🔧 Required Configuration
|
|
📊 Creating the Vector Index (Cosmos DB Portal or SDK)
|
|
DiskANN parameters:
- Type:
diskANN(Cosmos DB’s high-performance ANN algorithm) - Dimensions: 1536 (matching text-embedding-ada-002 output)
- Similarity metric: Cosine distance (default)
⚡ Performance Considerations
⏱️ Query Latency
- P99 latency: ~50-100ms for vector search (3-5 results)
- Embedding generation: ~200-300ms (OpenAI API call)
- Total RAG cycle: ~300-500ms (acceptable for real-time agent interactions)
📈 Scaling
- DiskANN shines at scale: Handles millions of vectors with minimal latency increase
- Cosmos DB auto-scaling: RU/s adjusts based on query load
- Partition strategy: Use
sourceDocumentorsiteas partition key for geo-distributed queries
💰 Cost Optimization
- Embedding caching: Store embeddings once, query thousands of times
- Batch processing: Vectorize documents offline during ingestion
- Shared throughput: Use database-level provisioned throughput for predictable costs
📝 Lessons Learned
1️⃣ Chunk Size Matters
- Too small (50 words): Loses context
- Too large (2000 words): Dilutes semantic signal
- Sweet spot: 200-500 words per chunk (1-2 paragraphs)
2️⃣ Metadata Enrichment
Include metadata in embeddings:
|
|
This helps the model understand document provenance during embedding generation.
3️⃣ Observability is Critical
Log:
- Embedding generation time
- Vector search latency
- Similarity scores (how confident is the match?)
- User query → retrieved documents (for quality tuning)
🌍 The Bigger Picture: RAG for Archaeological Discovery
This isn’t just about searching documents—it’s about institutional memory. Every excavation, every field report, every expert observation becomes queryable knowledge that:
- Prevents redundant work: “Has this site been surveyed before?”
- Surfaces forgotten insights: A 1980s journal entry mentions pottery—relevant to today’s AI analysis
- Democratizes expertise: Junior archaeologists access decades of senior knowledge instantly
- Scales human intelligence: AI agents synthesize patterns across 100,000+ documents (impossible manually)
Vector search transforms data graveyards (PDFs in folders) into living knowledge graphs.
📚 Next in the Series
Blog 7: [Scalable Container-Based Processing Architecture] - How Azure Container Apps orchestrate LiDAR and satellite processing at scale, with event-driven auto-scaling based on upload queues.
💻 Source Code
- Vector Repository:
Archaios.AI.Infrastructure/Repositories/Cosmos/CosmosDbVectorRepository.cs - Search Plugin:
Archaios.AI.DurableHandler/Agents/Chat/Plugins/ChatVectorSearchPlugin.cs - Configuration:
Archaios.AI.DurableHandler/Program.cs(lines 113-118)
All code examples in this blog are from the actual Archaios production codebase—no fictional implementations.
Vector search isn’t about replacing archaeologists—it’s about giving them superhuman recall of every relevant document ever written about a site. That’s the power of semantic knowledge retrieval.
If you find this post helpful, please consider sponsoring.
