Leveraging Azure Cosmos DB for Efficient Data Retrieval in DTDL CustomerCare

1. About this blog
Welcome back! In this blog, we’ll explore vector databases and their use cases in building LLM applications. Specifically, we will utilize Azure Cosmos DB for Mongo vCore as our vector database solution.

By the end of this blog you should be aware on how to work with Azure Cosmos DB for Mongo vCore and make use of it’s vector search capability.
2. Vector database and embeddings
Vector database
A vector database is a special type of database that stores data as high-dimensional vectors. These vectors can have hundreds of dimensions, with each dimension representing a specific feature or property of the data object. For you to understand it better and visualize please visit https://projector.tensorflow.org/
Here’s a simple breakdown:
Imagine you have various items, and each item has many characteristics. A vector database takes these characteristics and turns them into a vector, which is like a long list of numbers. Each number in the list represents one characteristic of the item. For example, if you’re storing information about different cars, one dimension could represent the car’s speed, another its color, and another its price.
This vector data is usually generated by something called an embedding function, which transforms the original data into these vectors.
It’s important to note that a vector database is different from vector search or a vector index. While vector search is about finding similar vectors (like finding similar items in a search engine), and a vector index is about organizing these vectors for efficient searching, a vector database is a full-fledged data management system.
For example, if you’re using Azure Cosmos DB for Mongo vCore as your vector database, it helps store the vector data, manage it efficiently, and ensure it’s secure and scalable. This makes it easier to handle large amounts of data, perform complex searches, and provide accurate and quick responses to queries.
To better visualize the search capability, use the TensorFlow Projector tool and typing in a query like “Sleep.” As you type, all similar words appear in the visualization, based on their distance metrics.

Embeddings
Embeddings are a powerful technique used in AI to represent words or data as vectors in a high-dimensional space. Think of these vectors as arrows with both direction and length. Here’s a simplified breakdown:
Embeddings place data in a space with many dimensions, beyond what we can normally perceive. They assign similar words or data similar vectors, while different ones get different vectors, helping measure how related words or data are. This allows for operations like addition, subtraction, and multiplication, making them valuable for AI models to understand and process the meaning and context of words or data.
When we transform sentences, paragraphs, or pages of text into embedding vectors, search queries are converted into embedding vectors as well. These vectors are then compared with existing ones to find the most similar matches, much like search engine results. Even if an exact match isn’t found, a set of results ranked by similarity will be provided.
Azure OpenAI embeddings use cosine similarity to calculate how similar documents and queries are by measuring the angle between two vectors. Even if the documents are far apart in size, a smaller angle means higher similarity, ensuring effective matching of documents and queries for better search results.
For example, if you have a PDF with various FAQs about Deutsche Telekom services, embeddings help by extracting structured data from the PDF using Azure Document Intelligence, breaking down the information into smaller chunks, and storing them in Azure Cosmos DB. When a user asks a question, the query is converted into an embedding vector and searched in the database, retrieving the most relevant chunks to provide a response. This process creates a more efficient and accurate customer support system by leveraging embeddings to understand and process queries effectively.
3. Azure Comsos DB for Mongo vCore
Azure Cosmos DB for MongoDB vCore’s vector search capability is a significant feature that offers several benefits for building cost-efficient LLM (Large Language Model) applications.
Why It Is Better Than AI Search or Plain Vector Databases
- Holistic Integration - Unlike standalone vector databases or AI search solutions, Azure Cosmos DB for MongoDB vCore offers a unified platform that integrates vector search with your existing NoSQL database. This seamless integration simplifies data management and enhances performance.
- Reduced Complexity - Managing a single database system that supports both traditional and vector search queries reduces the architectural complexity of your applications. This leads to easier maintenance and lower operational overhead.
- Enhanced Functionality - The combination of vector search with NoSQL database features allows for richer and more complex queries, providing greater flexibility in building sophisticated applications that can leverage both types of data.
- Cost and Resource Efficiency - By removing the need for separate vector databases, you avoid the cost and resource redundancy associated with maintaining multiple systems. This makes your overall system more efficient and cost-effective.
Setup Cosmos DB for MongoDB vCore
We already have well documentation for setting up this in Azure here
Once your setup is complete, you can store the embeddings created in our previous blog in the database along with their metadata.
|
|
Connecting to MongoDb
I recommend using MongoDB Compass for analyzing data and verifying if indexes are created. You can download it here
After downloading, connect to your MongoDB instance using the connection string provided in the Azure portal.
For those testing the authentication flow in the live app, please note it won’t send you the SMS as we only have one customer mapped in the database.
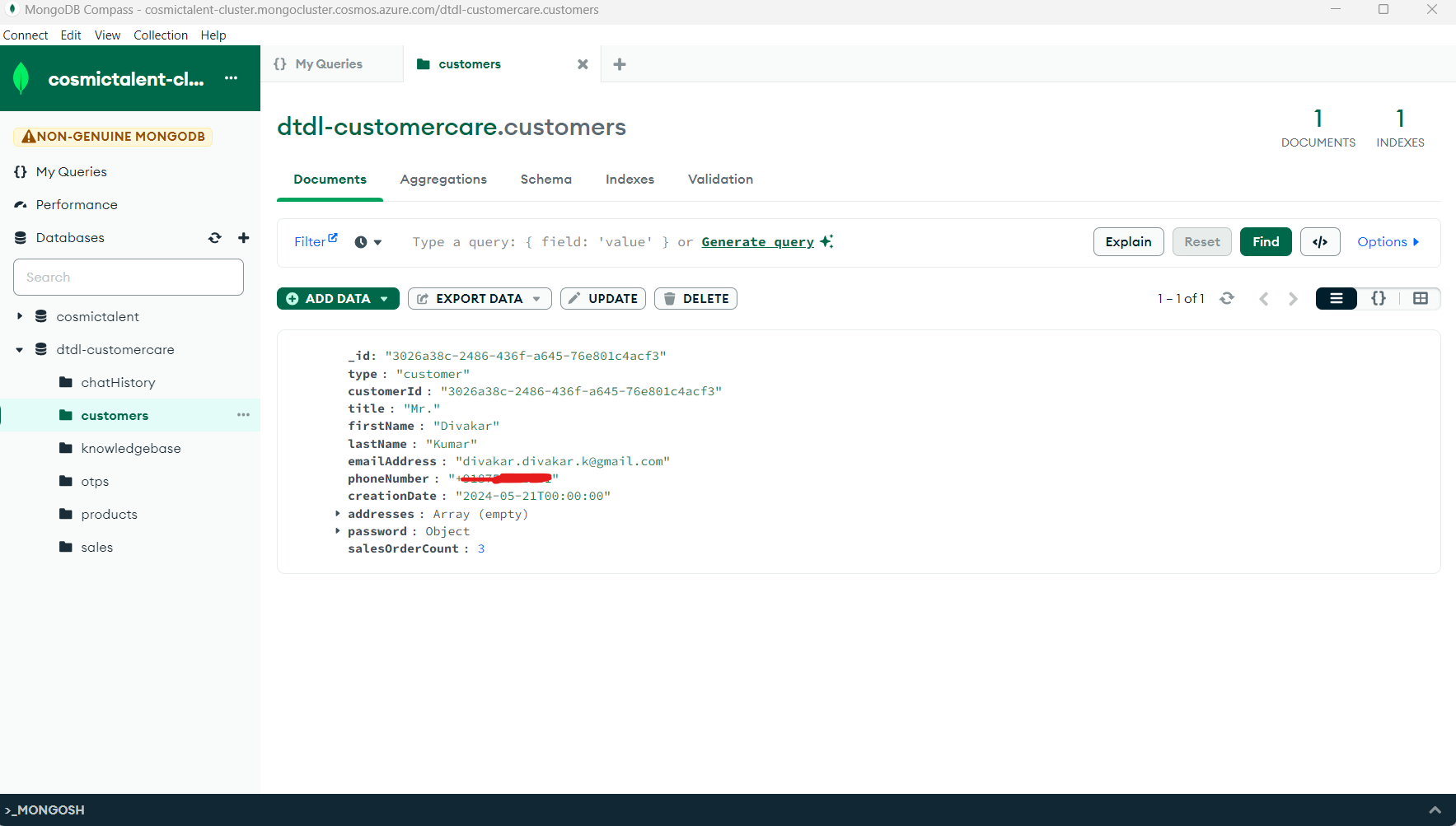
I’m not planning to expose an endpoint to add customers to this collection, as it might lead to a high volume of requests to my free Twilio account. If you need access, please reach out to me personally on LinkedIn .
4. Source code
6. Live URL
https://dghx6mmczrmj4mk-web.azurewebsites.net/
CAUTION : If the site is slow, it is due to the serverless infrastructure used for this application.
Sponsor
If you find this post helpful, please consider sponsoring.
