Building the Backbone: Data Ingestion and IVF index creation for DTDL's Autonomous Assistant

1. About this blog
Welcome back! In this blog, we will learn how to prepare data for our retrieval process. There are various approaches to this, but we’ll use Azure Document Intelligence to extract information from unstructured documents. By the end, you’ll know how to:
- Work with the Azure Document Intelligence Layout model 📄
- Perform custom chunking and add metadata 📝
- Vectorize data into embeddings 🔍
2. Dataaaa
The nature of data can vary greatly and often includes unstructured formats such as PDFs, audio, video, and images. Our first step is to prepare this data so we can retrieve relevant information from it. While we could use a simple parser to get text content from PDFs, not all information will be in plain text. PDFs can contain complex tables, images, and other elements that might confuse LLMs if extracted through a simple parser. Therefore, we need to rely on advanced services that handle this task more effectively.
In our case, since DTDL maintains PDFs for FAQs, we used Azure Document Intelligence to extract information.

3. Architecture
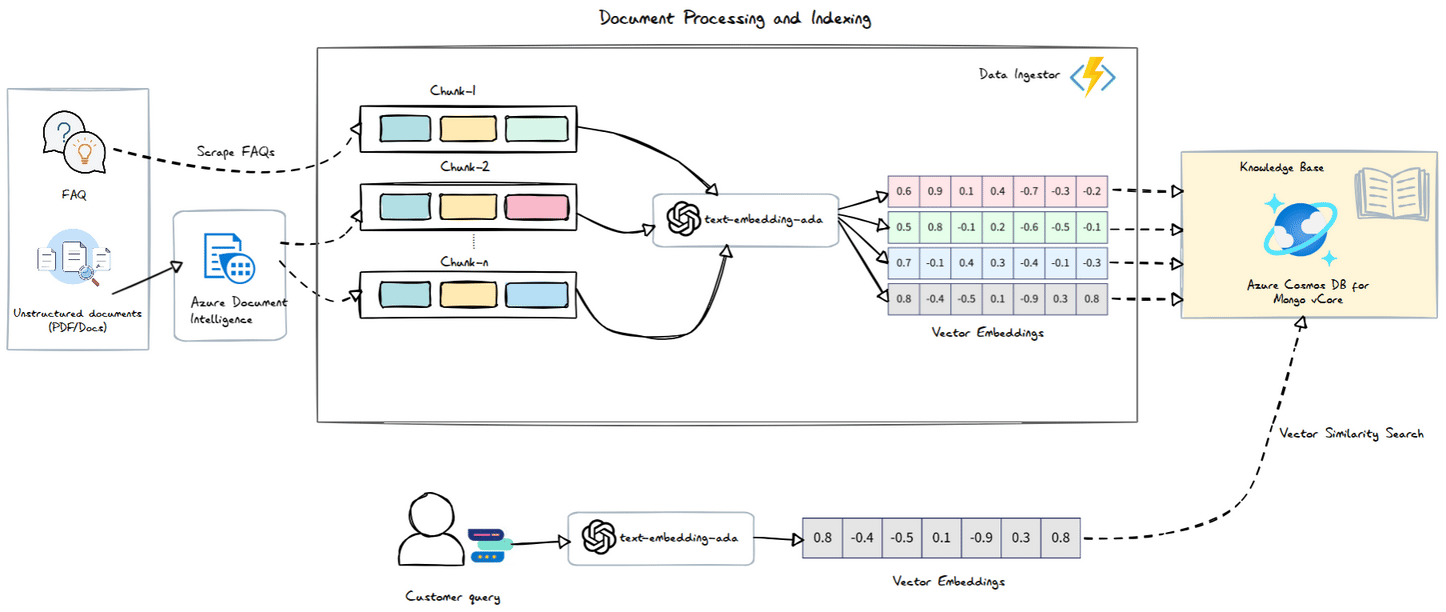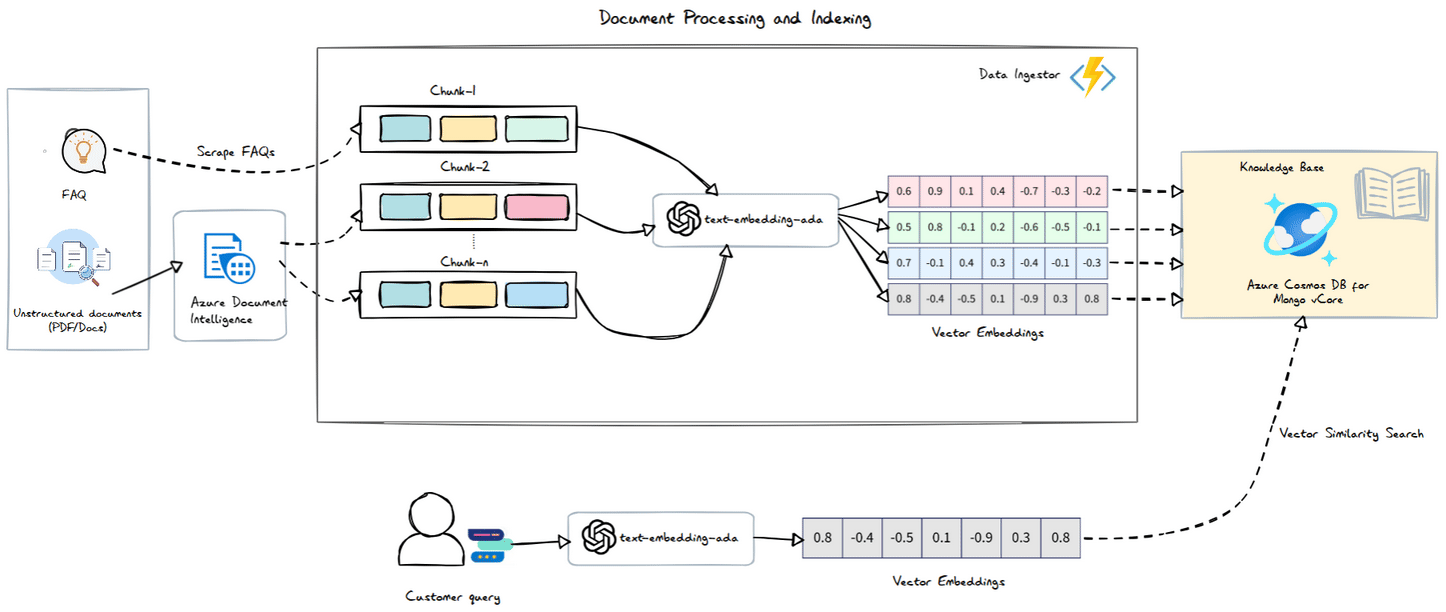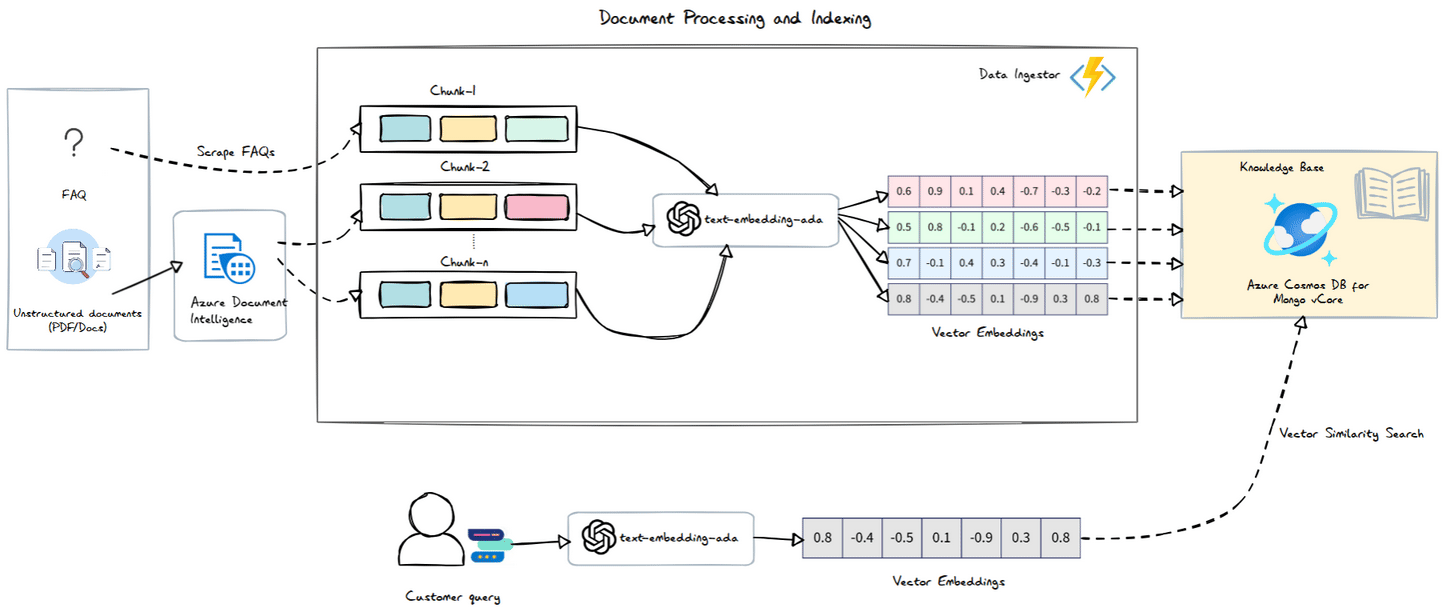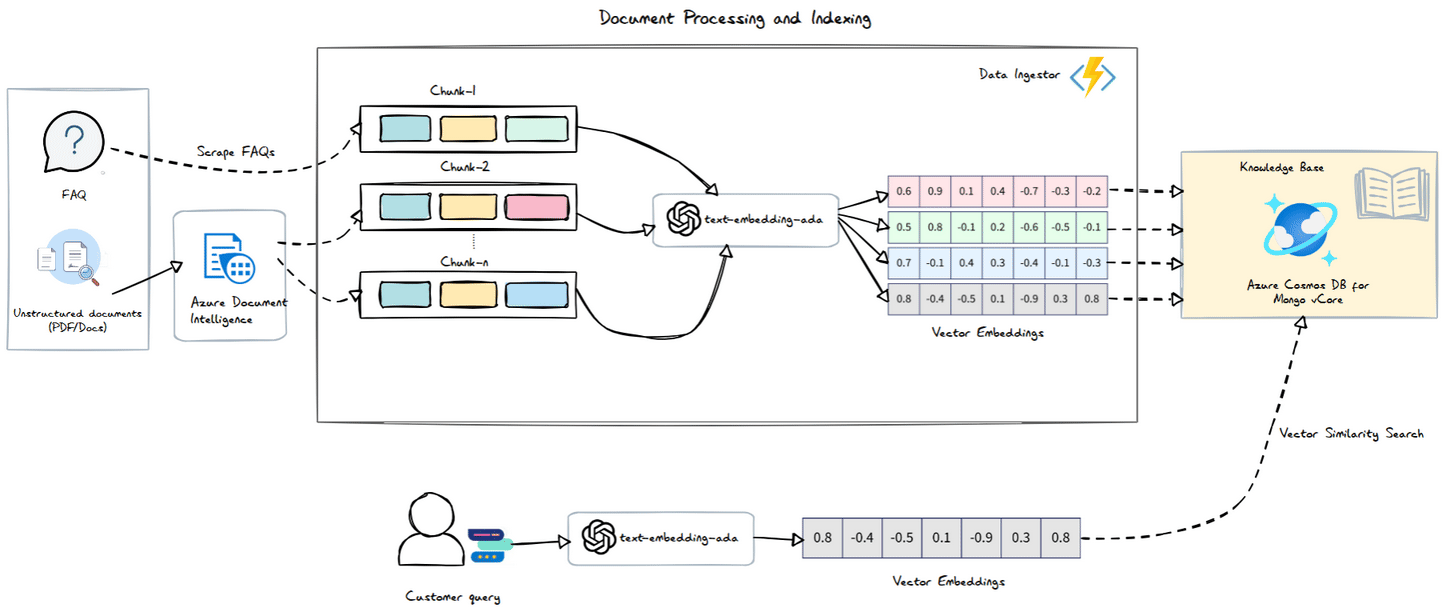
Azure Document Intelligence
Azure AI Document Intelligence is a cloud-based service that automates document processing by extracting structured data from various document types using prebuilt, custom, and document analysis models. It supports diverse use cases such as invoice processing, identity verification, and tax form management, and offers integration through APIs and SDKs.
Step 1: Create Resource
Ah, I’m not going to bore you with the details on how to create it. Please follow this doc that provides all the steps to create this service in the Azure portal.
Step 2: Decide on which model to use
If you have been following my earlier blogs, you know that I choose the Custom model to extract information from documents. However, I haven’t covered when to use each model in detail. So, here is a detailed mindmap for choosing the right model for your needs:
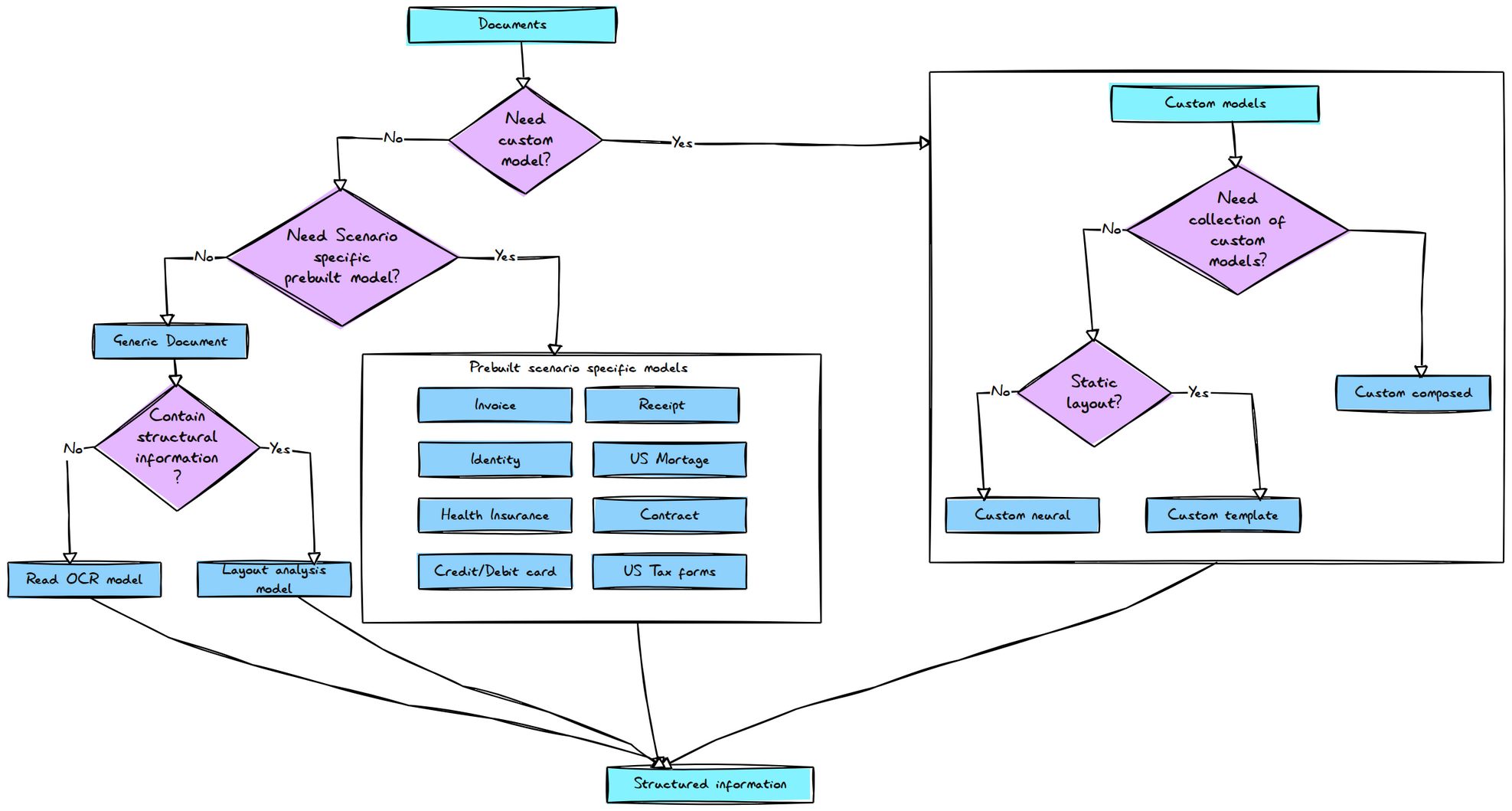
Step 3: Analyze PDF with layout model
- Go to Azure Document intelligent studio
- Select layout model
- Upload the PDF file you want to analyze
- Click on Run analyze button
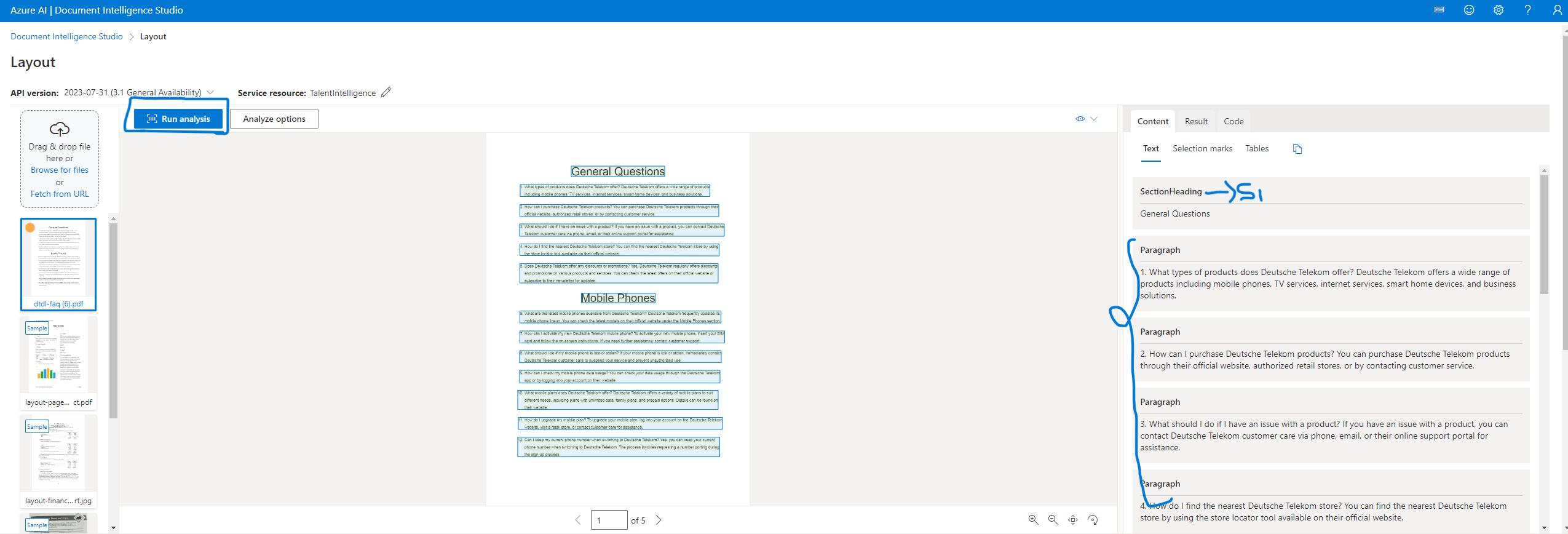
The Azure Document Intelligence service processes documents and returns the content organized into sections and paragraphs. This allows us to easily create chunks based on these sections and their associated paragraphs. The logic is straightforward: each paragraph is grouped under the most recent section title until a new section title is encountered.
Azure Function - Data Ingestor
Next, we need to implement this logic in our function app. We’ll set up an HTTP trigger for uploading files, and in the handler, we’ll use the Azure Document Intelligence .NET SDK to extract information from our FAQ PDF.
Here’s the code logic for grouping sections by headings:
|
|
Once we have our sections, we’ll proceed to chunk them, vectorize the chunks, and store the results in Azure Cosmos DB.
|
|
5. Source code
6. Live URL
https://dghx6mmczrmj4mk-web.azurewebsites.net/
CAUTION : If the site is slow, it is due to the serverless infrastructure used for this application.
Sponsor
If you find this post helpful, please consider sponsoring.
